
Debouncing in Queueing Systems: Optimizing Efficiency in Asynchronous Workflows
Explore backend message queuing systems, implementing debouncing in Postgres, and simplifying the process with Inngest.
Dan Farrelly· 2/28/2024 · 9 min read
When developers talk about debouncing, it's most often discussed as a front-end development technique to handle issues in user interfaces. It's also quite a useful technique to apply to backend message queuing systems. In this post we'll cover:
- what debouncing is,
- when to use debouncing with queues,
- how to implement this in a simple Posgtres queue,
- and how you can use this feature with Inngest.
What is debouncing
Debouncing is used to avoid unnecessary executions. At its core, it is a technique to ensure a particular task or operation is executed only once after a specified delay since its last invocation, even if triggered multiple times within that delay.
A classic front-end example involves an auto-complete input where a user's actions, like typing, could trigger duplicate work by fetching search results. The goal is to send a single action, such as an HTTP request, only after the user has finished typing.
When to use debouncing in queuing systems
Debouncing within queueing systems is most important when you're aiming to improve efficiency of execution. It might be a user that triggers a job that's costly to run or some event that triggers a larger job to execute that is wasteful to have to re-run. Here are couple of specific situations where you may want to add debouncing into your queue and worker system:
- Cost efficiency with AI / LLMs. Leveraging any sort of AI is expensive. Whether you're using OpenAI's APIs or running your own models on GPU-optimized instances, leveraging AI can be costly. Depending on what is triggering your AI code to run (for example, a user saves data in a form) it may be triggered twice within a short time window. Debouncing this trigger can help ensure there is no wasted re-work with AI.
- Data synchronization and integrity. In systems involving data synchronization or batch processing, it's often essential to ensure that operations are performed only when all relevant changes have been completed. Debounce can facilitate this by delaying execution until a predefined idle period has passed, ensuring data integrity and consistency.
- User interface interactions and auto-save. Similar to the example mentioned above, background jobs are often triggered by user actions that save data. If a user saves the same data in quick succession, or perhaps the front-end implements auto-save, it is likely that multiple background jobs will be triggered. Adding a debounce delay to your background job can make your system more efficient.
- Deduplicating chatty webhook events. While webhook events are great to integrate with third-party systems, some webhook providers, for example Intercom, may trigger multiple events in short succession for the same or similar actions that you only need to react to once. Also, often when building webhook integrations, you'd design for eventual consistency, so debounce delays are acceptable.
While debouncing is traditionally associated with frontend development and user interface interactions, its principles and techniques can also be applied effectively in backend software development to optimize resource utilization, mitigate performance bottlenecks, and enhance the scalability and reliability of distributed systems and event-driven architectures.
How to implement debouncing in a message queue
Depending on what backing queue you use, implementing debounce can be simple or difficult. At the basic level, your system needs to be able to schedule a given message at a timestamp in the future (the delay) and when the same message is sent, the currently scheduled message's timestamp is “pushed” back by the delay amount again. Your queue then must only pick up messages that are ready (the current timestamp).
Here we'll cover a basic implementation of a Postgres queue and look at how to add debounce. There are more advanced techniques for queuing in Postgres, but we will not cover that here.
First, we'll create a simple debounce_job_queue table in our database. It will have a job id , a job_type , a current status for the job, a payload for relevant job data, and a scheduled_at timestamp. Lastly, we'll add a debounce_key which will be what we'll use to de-duplicate and delay work.
CREATE TABLE debounce_job_queue (id SERIAL PRIMARY KEY,job_type VARCHAR(64),status VARCHAR(64),payload JSONB,scheduled_at TIMESTAMP,debounce_key VARCHAR(64));
As we want to de-duplicate jobs waiting the queue, we'll add a unique index to ensure that there is only one matching job that is 'QUEUED' at a given time.
CREATE UNIQUE INDEX debounce_key_statusON debounce_job_queue(debounce_key, status)WHERE status = 'QUEUED';
Creating a new job in this queue is a relatively straightforward insert, but we add a few things that help us implement debounce:
- Create a deterministic
debounce_keyusing a hash of the job's type and payload JSON data. Alternatively, this could be any unique piece of data like a user's ID. - Allow the calling function to specify a delay when setting the
scheduled_at. - Handle conflicts with existing queued items with an
UPDATEto the existing item'sscheduled_atwith the specific delay. This is where the debouncing happens.
We'll use the @vercel/postgres library's simple sql here, but your favorite library will do just fine.
import { crypto } from "node:crypto";import { sql } from "@vercel/postgres";async function enqueue(jobType, payload, delay = 0) {const json = JSON.stringify(payload);const debounceKey = crypto.createHash("sha256").update(jobType + json).digest("hex");return await sql`INSERT INTO debounce_job_queue (job_type, status, payload, scheduled_at, debounce_key)VALUES ('${jobType}', 'QUEUED', '${json}',now() + INTERVAL '${delay} seconds', ${debounceKey})-- If the item is already QUEUED, update the scheduled at w/ the delayON CONFLICT (debounce_key, status) WHERE status = 'QUEUED'DO UPDATE SET scheduled_at = now() + INTERVAL '${delay} seconds';`;}
The code above may appear complex at first, but the magic happens in the ON CONFLICT statement. Our unique index ensures that two identical jobs cannot be 'QUEUED' at the same time. When the query attempts to insert a job and there is an identical job that is QUEUED, the conflict statement is executed and the existing job's scheduled at is updated with our delay to push it back.
To query for available jobs, we'll also now use our scheduled_at timestamp to ensure that our function only fetches jobs that are ready to be processed. When jobs are debounced and the scheduled_at is pushed into the future, that prevents our query from fetching that job.
In our query, we'll also update the status to PROCESSING to mark that this job should not be picked up by any other worker and that it shouldn't be debounced again as it's being executed. In our code, we'll omit the worker polling logic and focus on the query. We'll use SKIP LOCKED here to prevent only query for rows that are locked due to being updated elsewhere.
async function getQueueItem(jobType) {return await sql`UPDATE debounce_job_queueSET status = 'PROCESSING'WHERE id = (SELECT id FROM debounce_job_queueWHERE status = 'QUEUED' and scheduled_at <= now() + INTERVAL '2 minute'ORDER BY scheduled_at ASCFOR UPDATE SKIP LOCKEDLIMIT 1)RETURNING id, payload;`;}
That's it! In your own worker code you'll want to also DELETE this item from the queue table when it's done processing (or similar). If you are implementing a debounce queue in Postgres, you may want to additionally consider:
- Adding other indexes to your table for performance.
- Adding a job expiration timestamp and clearing of expired jobs.
- Adding a column to track the number of attempts to process a given item and handling a maximum number of retries.
- Implementing a dead letter queue.
- Learning more about using
SKIP LOCKED.
Next, we'll compare this to implementing debounce with Inngest.
How to debounce with Inngest functions
Inngest's architecture combines an event stream, queues, and durable execution into a single reliability layer for your application. With Inngest's internal queueing system, you can easily debounce jobs.
The main differences to the above example is that with Inngest:
- You send events instead of messages.
- You define functions which each has their own queue(s) created automatically for you.
- Inngest calls your function for you, so you don't need to implement polling or similar in a worker.
- You can define your debounce key using any piece of data within your event's payload.
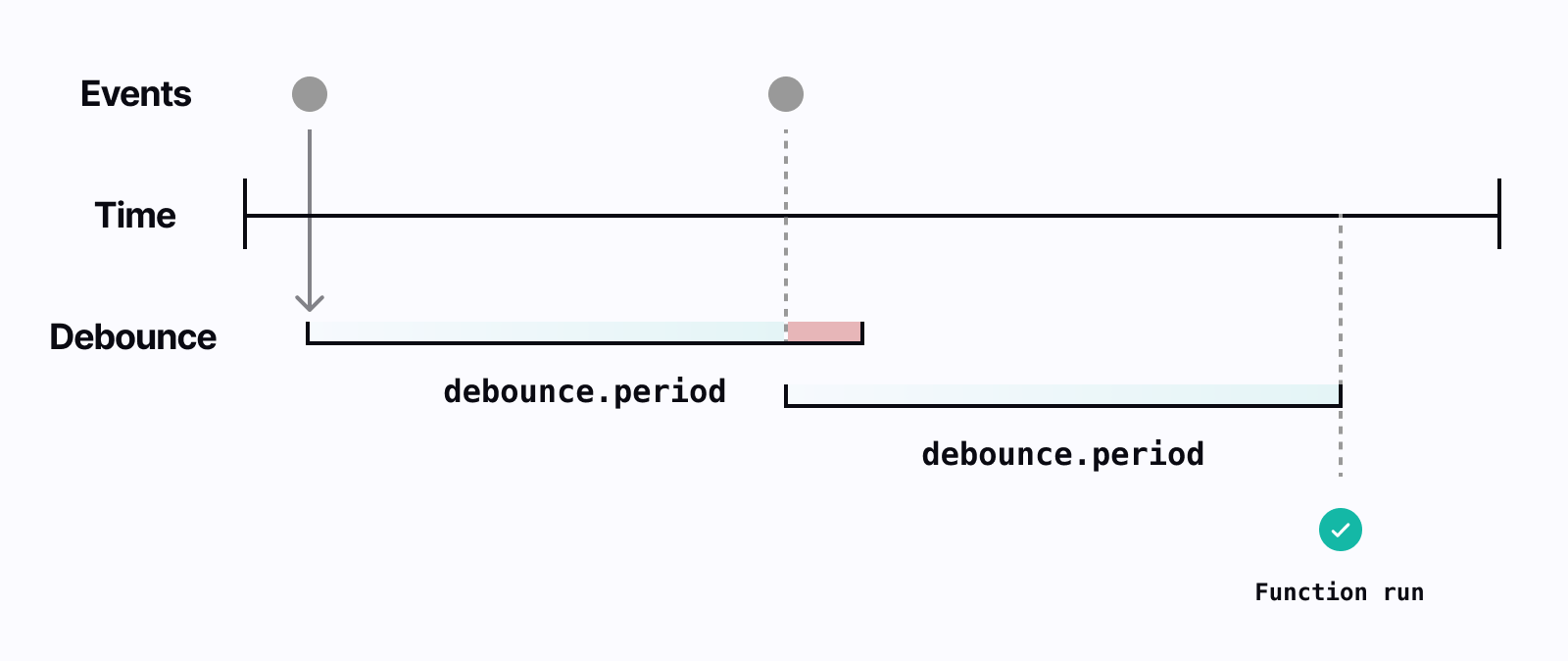
Configuring debouncing for an Inngest function is a couple of lines of code. In our example below, we'll create a function that generates suggested titles for a blog post every time a user saves a draft. We'll add a debounce period of one minute and we'll set a debounce key to only debounce based off the given blog_post_id . Setting the key will make sure that each unique blog post will be separately debounced.
const generateIdeasFunction = inngest.createFunction({id: "generate-ideas-via-open-ai",debounce: {period: "1m",key: "event.data.blog_post_id",},},{ event: "blog/draft.saved" },async ({ event, step }) => {/* call OpenAI */},);
For more information on this, check out our guide on debouncing or check out our quick start tutorial to learn the basics of Inngest.
Conclusion
Debouncing is a powerful and highly useful technique in many queueing use cases. This is why we built it right into Inngest so any developer can use it with any function with ease. We'd love to hear what other use cases where you use debouncing and any other features that you have added!
If you found this blog post interesting, check out another one on how we've built our multi-tenant queuing system.